First time pretending to be a Bayesian, and trying RStan.
Author
Kenneth Hung
Published
September 25, 2020
I did not really much statistical training in my undergrad days, and my knowledge of statistics is pretty much confined to whatever grad level statistics classes Berkeley offered — 99% of those was frequentist — so I lack the Bayesian exposure that most statistics undergrad would have received. So when something slightly Bayesian (does empirical Bayes count?) showed up, I decided to teach myself using Gelman et al. (2013).
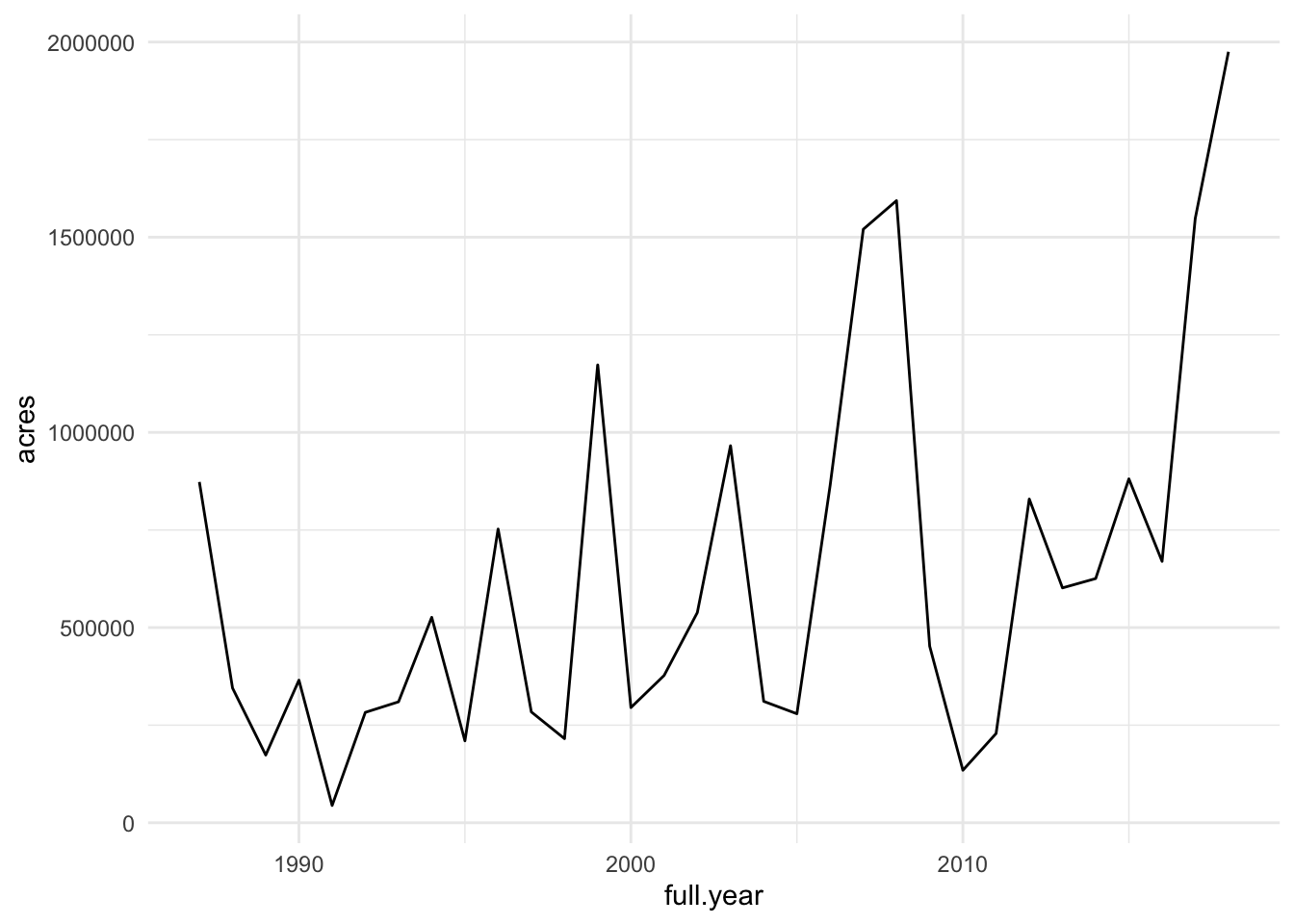
It is hard to learn something new without any examples, and I happen to stumble upon this tweet:
Trend line can be misleading, and there are good years too. But certainly it looks like bad years had become worse. Just curious, where can I find the data itself for educational purposes?
For execution on a local, multicore CPU with excess RAM we recommend calling
options(mc.cores = parallel::detectCores()).
To avoid recompilation of unchanged Stan programs, we recommend calling
rstan_options(auto_write = TRUE)
Attaching package: 'rstan'
The following object is masked from 'package:tidyr':
extract
Using the default priors, I ran a Bayesian linear regression. I have to say, seeing the chains running and utilizing my new laptop’s computation power was very exciting.
model.stan <-"data { int<lower=0> N; vector[N] x; vector[N] y;}parameters { real alpha; real beta; real<lower=0> sigma;}model { y ~ normal(alpha + beta * x, sigma);}"fit <-stan(model_code = model.stan,data =list(N = N, x = data$year, y = data$acres),iter =5000)summary(fit)$summary
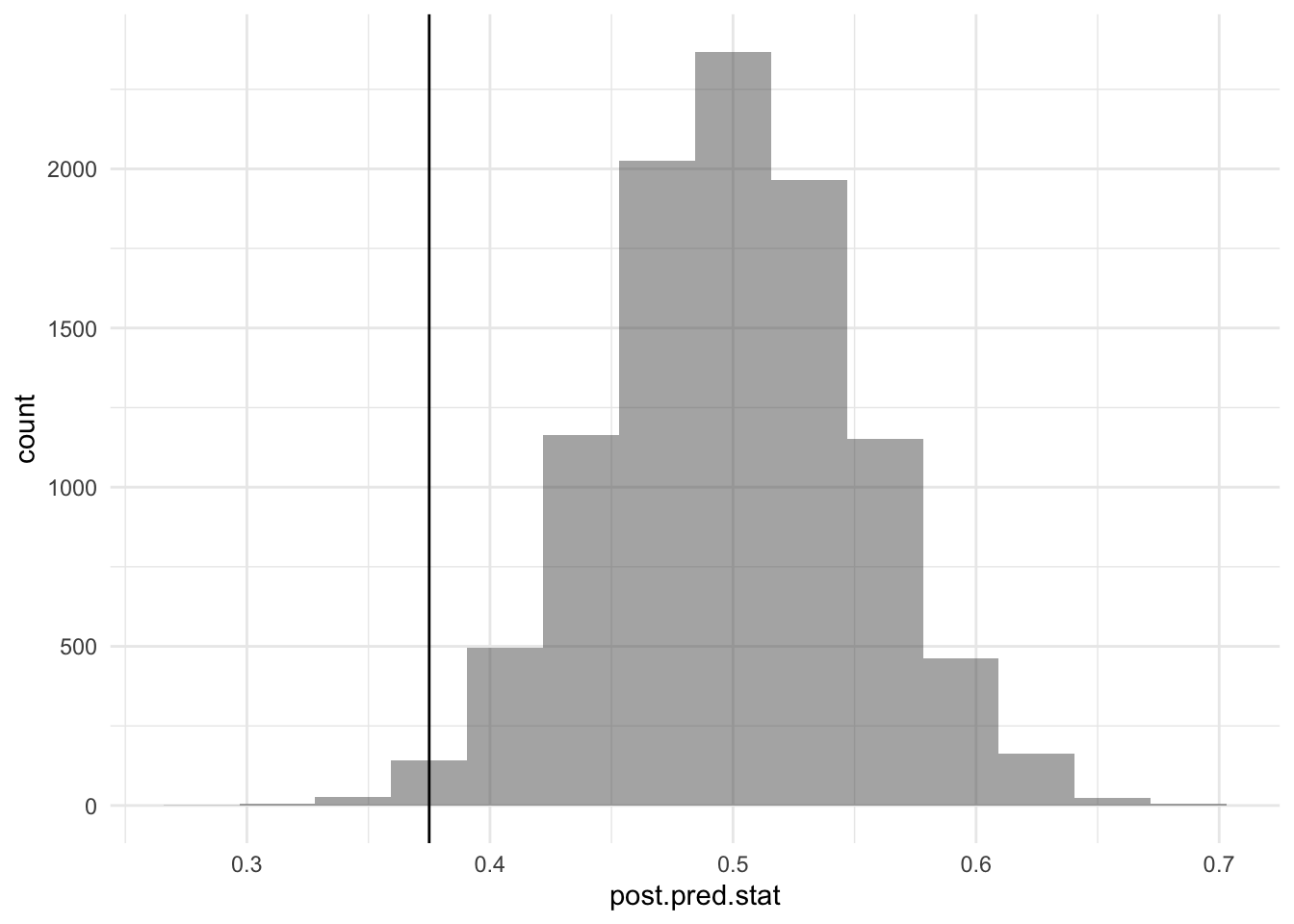
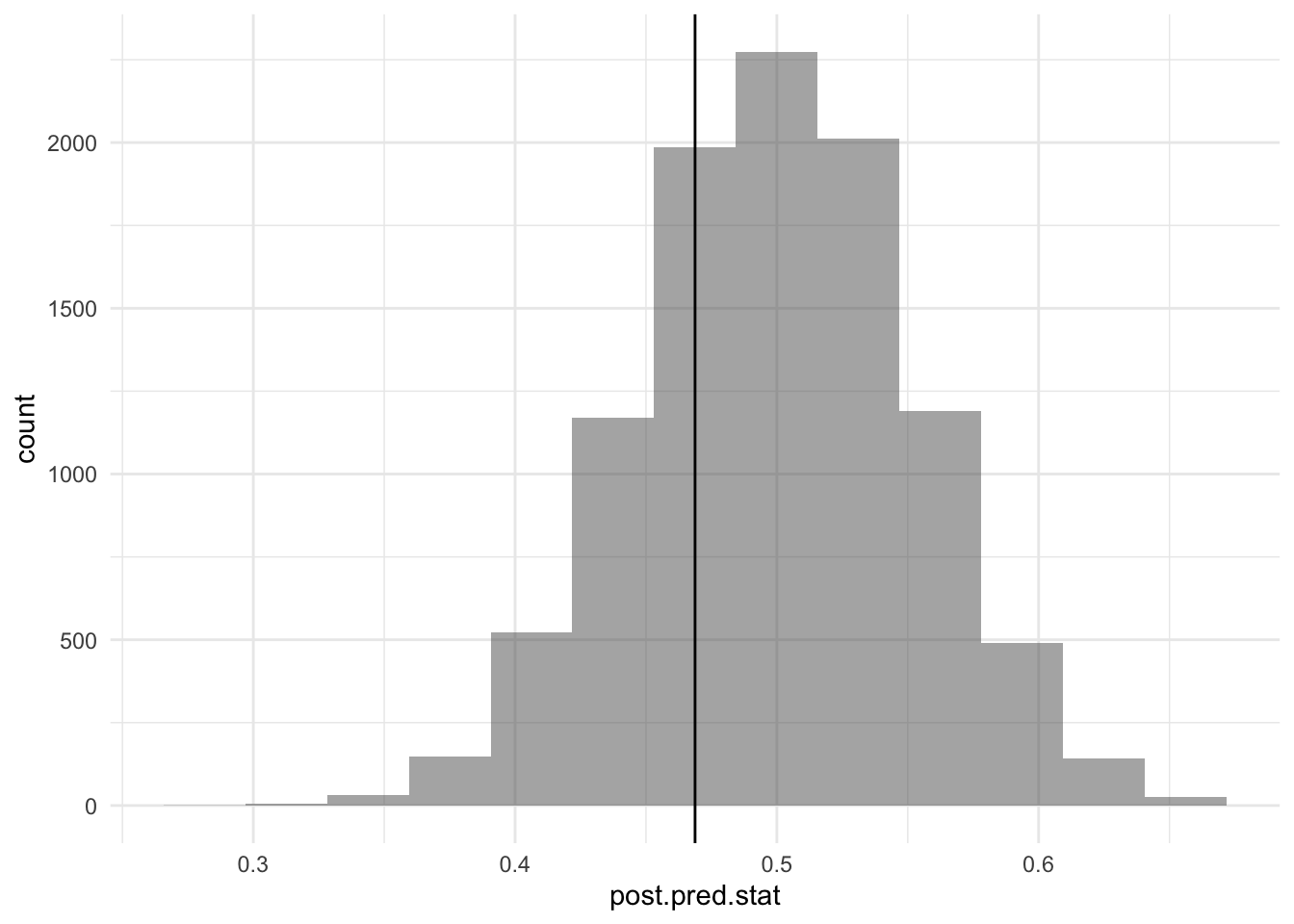
Since all Bayesians do is do posterior draws, I don’t find it hard to understand the result. But what matters the most to me is that the data is fit well. As BDA would suggest, I should do a posterior predictive check, specifically something that would demonstrate my suspicion that linear model isn’t a good fit. By looking at the time series, I would guess that there are fewer positive residuals than negative ones. So I used the proportion of positive residuals after OLS as the test statistic. Embarrassingly it took me a long time to realize how to do a posterior predictive check for regression, the most basic example in Chapter 14 surprisingly did not emphasize this part.
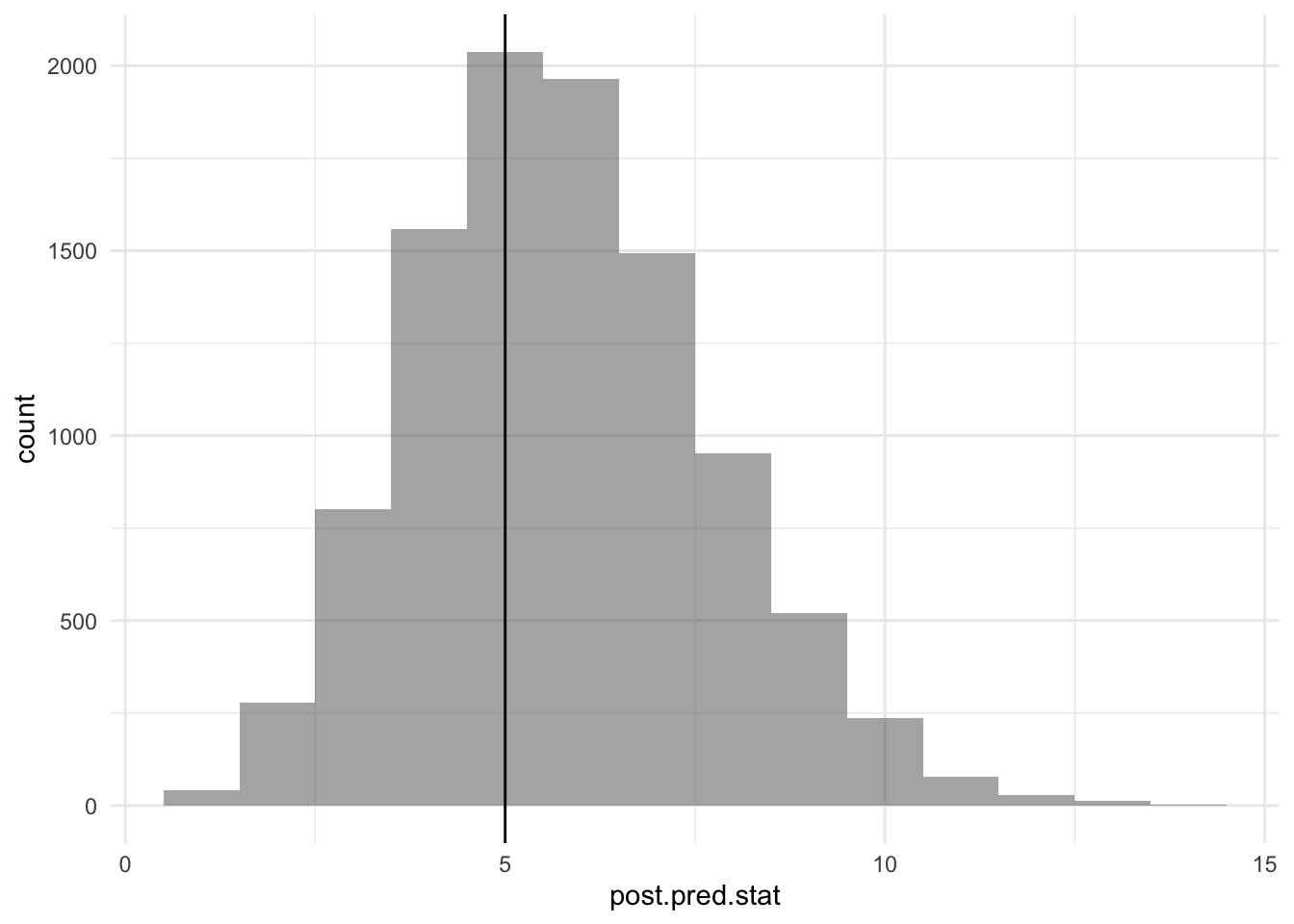
Much better! Of course the model is not going to be correct, but we just need to keep checking for statistics that we care about. One idea I had is the number of times a new record is set. From the time series, it is 5 — we will count the very first year, not that it really matters. I thought this may be revealing if there is a lot of autocorrelation in the time series — for example, the more acres are burnt the previous year, the less there is to burn the year after.
Not too bad! For both model it looks like the slope is positive. There are many other data that would have been relevant to this analysis, such as the rainfall the year before and other climate data. There are also more sophisticated things such as Bayesian ARIMA that I could do (but I don’t know how), but hey, there are only 32 points in this dataset.
References
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., and Rubin, D. B. (2013), Bayesian Data Analysis.