A recent meta-analysis on choice architecture, or “nudging”, but people do not seem to agree on if “nudging” works.
Author
Kenneth Hung
Published
August 27, 2022
As usual, I am not a psychologist, and do not even run experiments myself, so the model I am discussing here is going to simplistic. But if we are willing to assume a very simple publication bias model, where only statistically significant results are published (a.k.a. “file-drawer effect”), then we can apply the methods from my paper with Will (Hung and Fithian 2020), and answer questions such as
Does any “nudging” experiment have real effect? How many of the experiments?
What happens if we counter the file-drawer effect with a more stringent threshold?
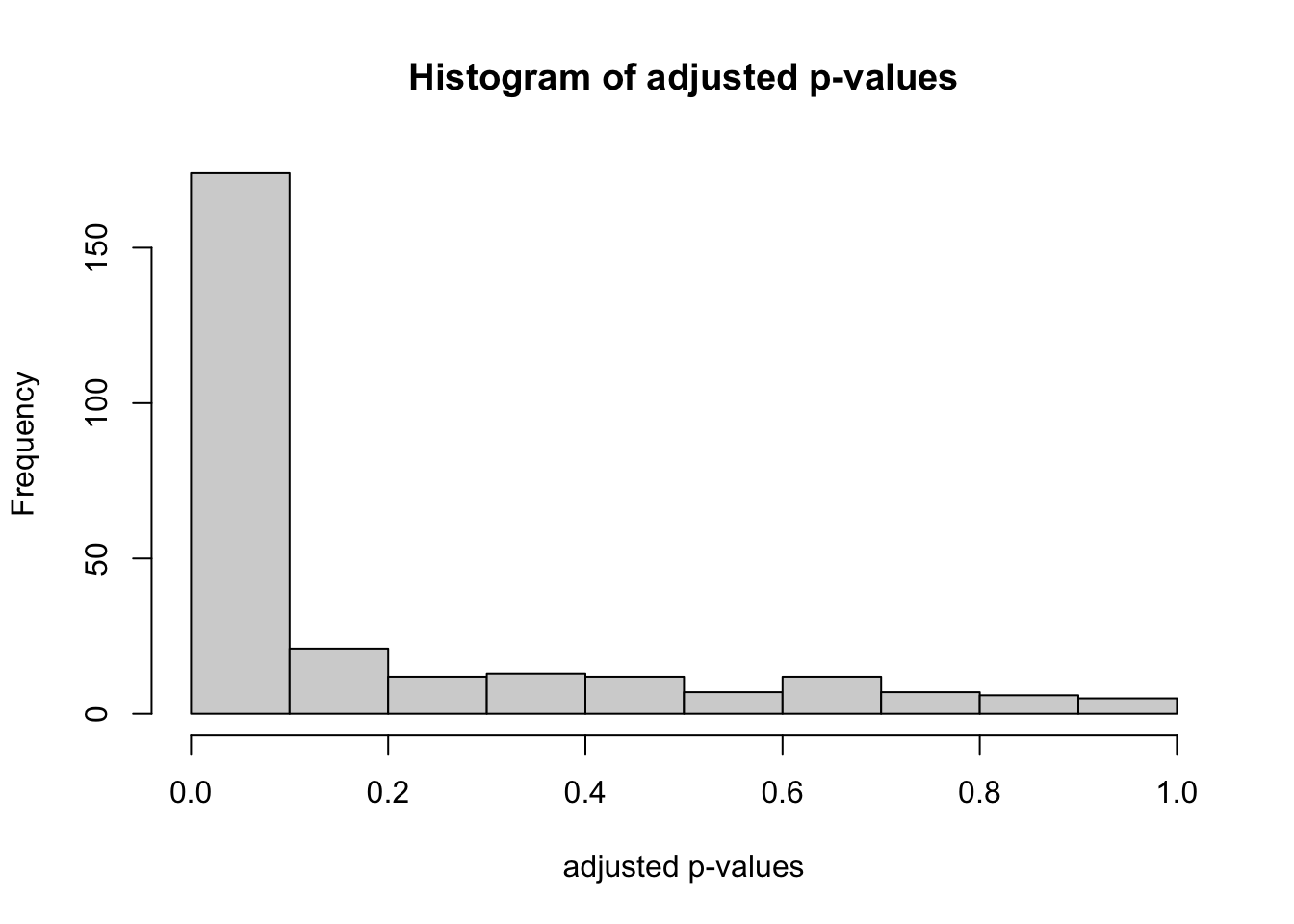
So first of all, we are going to only look at p-values that are smaller than \(0.05\), and adjust them by division by \(0.05\), as in our aforementioned paper, or Zhao et al. (2018).
The first question can be answered by our method, and for convenience, we will just pick \(\lambda\) to be \(0.5\). All adjusted p-values will fall in one of these categories:
Null
Non-null
Total
Small (\(p \le 0.5\))
*
*
*
Big (\(p > 0.5\))
\(U\)
*
\(B\)
Total
\(V\)
*
\(R\)
Specifically, we want to make inference on the false discovery proportion (FDP), which is \(V / R\), since every experiment was deemed a discovery beofre. Equivalently, \(1 - V/R\) would indicate the proportion of experiments that has an actual effect. Intuitively, if \(B\) is not that large, \(U\) cannot be large and \(V\) cannot be so big either. Formally, we will be using the inequality (2) from the paper:
\[B \ge U \ge_{\text{st}} \ge \text{Binomial}(V, 1 - \lambda),\]
and rejecting unlikely large values of \(V\). As a side, we can also get a point estimate of the FDP.
internal.comparison <-function(pval, lambda) { R <-length(pval) B <-sum(pval > lambda) V_est <- B / (1- lambda) V <-0:R V_ucb <- V[max(which(pbinom(B, size = V, prob =1- lambda) >0.05))]data.frame(R = R,V_est = V_est,V_ucb = V_ucb,FDP_est = V_est / R,FDP_ucb = V_ucb / R )}internal.comparison(adj_p, 0.5)
In other words, at 95% confidence, at most 90 of the 269 are noise, meaning 179 of them have actual nonzero effect — but of course whether the effect is big enough to be meaningful is not up to me.
Would these numbers look better if we use a more strigent threshold? It just so happens that our paper also has a method for it!
We will not be using all p-values this time, but for the used ones, they will fall into one of these cells in this table:
Null
Non-null
Total
Small (\(p \le \alpha / 0.05\))
\(V_\alpha\)
\(T_\alpha\)
\(R_\alpha\)
Big (\(p > 0.5\))
\(U\)
\(W\)
\(B\)
Total
\(N_0\)
*
\(N\)
This time the inequality is more involved, from Lemma 1 in the paper (Did we make a typo in there?):
\[B = U + W \ge_{\text{st}} \text{Binomial}\left(N_0, \frac{\alpha / 0.05}{\alpha / 0.05 + 0.5}\right) + W \ge_{\text{st}} \text{Binomial}(N - T_\alpha, \beta).\]
But to use it, it is the same: we reject large values of \(V_\alpha\) on the basis of small values of \(B\), and get a point estimate for this on the side.
Hung, K., and Fithian, W. (2020), “Statistical Methods for Replicability Assessment,”The Annals of Applied Statistics, 14, 1063–1087. https://doi.org/10.1214/20-AOAS1336.
Zhao, Q., Small, D. S., and Su, W. J. (2018), “Multiple testing when many p-values are uniformly conservative, with application to testing qualitative interaction in educational interventions,”Journal of the American Statistical Association.